阿尔法狗(AlphaGo)彻底战胜人类意味着什么
 “你必须明白,这些人中的大部分还没有准备好去拔掉他们身上的控制物。他们中的很多人都如此习惯于、并且无望地依赖于这个控制系统,甚至会反过来维护它!”—《黑客帝国》
“你必须明白,这些人中的大部分还没有准备好去拔掉他们身上的控制物。他们中的很多人都如此习惯于、并且无望地依赖于这个控制系统,甚至会反过来维护它!”—《黑客帝国》
阿尔法狗与人类顶尖棋手的人机大战注定成为人工智能(Artifical Intelligence, AI)的里程碑事件,当AI变得越来越复杂,越来越聪明,以至于在多个领域全面超越人类的时候,那时的AI会是提高人类生产力和生活质量的好助手?抑或是彻底控制奴役人类的天网?现在还难以下结论,但可以肯定的是接下来数十年里AI对人类生活造成的冲击将是巨大的,本文就来说说阿尔法狗彻底战胜人类到底意味着什么。
1.“猫”和“狗”的野蛮生长
2012年,GoogleX的“猫”AI面世,纽约时报曾以《需要多少计算机才能正确的识别猫?16000台》为标题报道吴恩达领导的GoogleX实验室是如何训练机器认识猫的,最为特别的是,谷歌的猫AI不需要任何外界信息的帮助,它就能从数千万张图片中找出那些有猫的图片。传统的人脸识别是由程序员预先将整套系统编程实现,告诉计算机人脸应该是怎样的,电脑才能对包含同类信息的图片作出识别,而谷歌AI却是自己发现了‘猫’的概念,之前没有人告诉过它‘猫’是什么,也没有人类告诉它猫应该长成什么模样。
2009年,斯坦福大学华人教授李飞飞创立了全球最大的图像识别数据库-ImageNet,收集了大量带有标注信息的图片数据供计算机视觉模型进行训练,拥有1500万张标注过的高清图片,总共22000类。2012年,Hinton的学生Alex依靠8层深的卷积神经网络一举获得了基于ImageNet的ILSVRC比赛冠军,瞬间点燃了卷积神经网络研究的热潮,后来每年一度基于ImageNet数据库的深度网络对象识别比赛牵动着各大公司的心弦,2014年,Google深度网络在ImageNet ILSVRC的比赛中取得第一名,识别错误率为6.67%,2015年,微软研究院的Kaiming-He等4名华人提出的152层深度残差网络获得冠军,识别错误率仅为3.57%,超越人类的识别能力。2016年,李飞飞团队在教会了计算机去识别图像的基础上,让计算机像一幼儿一样学会看图说话,并会用“句子”进行交流,例如不止是说某张图里有只“猫”,还可以说“这只猫是坐在床上的”。
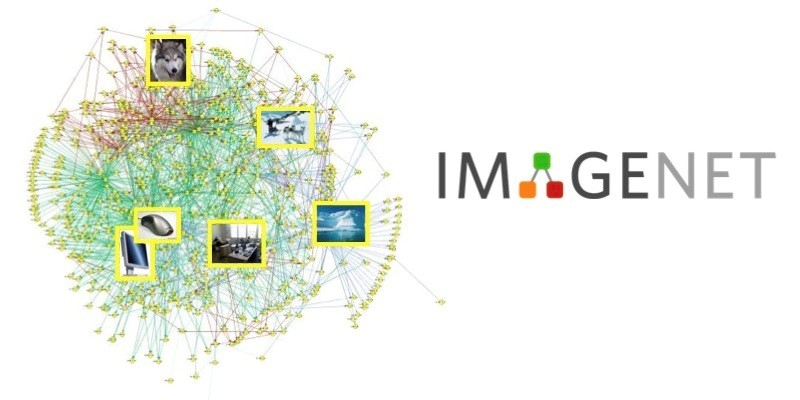 图1 imagenet图像识别数据库
图1 imagenet图像识别数据库
2016年,英国伦敦的DeepMind(2014年被谷歌收购)五年磨一剑,“狗”(AlphaGo)AI横空出世,与李世石人机大战4:1获胜。DeepMind的创始人杰米斯.哈萨比斯(Demis Hassabis)志向远大,其远景目标直指通用人工智能。虽然围棋艺术很主观,但AlphaGo却把围棋下得很客观,阿尔法狗设计了在每一步都会分析有什么影响,用哈萨比斯的话讲,AlphaGo已经可以模仿人的直觉,而且具备创造力,通过组合已有知识或独特想法的能力,不过这些能力目前仅仅局限于围棋。李开复关于阿尔法狗的评价很高:“AlphaGo是一套设计精密的卓越工程,达到了历史性的业界里程碑,这套工程不但有世界顶级的机器学习技术,也有非常高效的代码,并且充分发挥了谷歌在全球最宏伟的计算资源”。当然也有IBM的工程师匿名评价了他家的“沃森”(Watson)和“狗” (AlphaGo)的智力,声称沃森和AlphaGo的智力对比,基本上是狗和人的对比,Watson虽是人名,但是在阿法狗的智商面前,他才是真的狗。由此看来,大家应该知道阿尔法狗的技术有多牛了。从某种程度上讲,狗用的不是谷歌工程师写的一般意义上的算法,而是用的一套类人的学习框架(强化学习+深度学习),反复学习棋谱,自己和自己对战,类似于人类的学习方式,强化学习让狗拥有了初步的自我学习和博弈思考能力。
 图2 柯洁大战阿尔法狗
图2 柯洁大战阿尔法狗
当今世界,不少领域有着巨量信息和超级复杂的系统,例如电信、医疗、金融、天文、气候和经济领域,即使是领域内的专家也无法应对海量数据和系统的复杂性。同时,数以亿计的移动传感器、智能手机和互联网、无联网、企业系统还在源源不断地喂养数字地球,全球互联网和企业系统海量数据的爆炸式增长,给基于深度学习的人工智能插上了腾飞的翅膀。
我在前文《深度学习的深度价值是什么》曾提过,深度学习的核心技术是几十年前就提出的人工神经网络,如果将人工神经网络比为火箭发动机一代,那么深度学习就是火箭发动机二代,升级了训练方式(Hinton大神首创),加装了高性能计算配置(做游戏显卡起家的Nvidia居功至伟),最关键的是有了互联网和企业级巨头们的海量大数据燃料。为什么神经网络换马甲为深度学习之后,能获得突破性进展(图像、语音、翻译等多个领域接近或完败人类),上述三个方面的天时地利人和发挥了关键作用。另外我们都知道,伟大的东西往往很简单,好比爱因斯坦的EMC方程,深度学习也是一种朴素、简单、优美而有效的方法:像小孩搭积木一样简单地构建网络结构;性能不够,加层来凑的朴素思想,这种标准化、易用性的处理架构,极大降低了机器学习的难度,当然最关键还是效果,就某些应用领域而言,深度学习在大数据环境下的学习能力完败传统方法。 而阿尔法狗(AlphaGo)彻底战胜人类顶尖高手,就是深度学习技术应用的极致体现。大数据时代,AI生逢其时,就像哈勃望远镜一样,可以推进人类文明的进步,从治疗癌症、发现引力波、金融交易、安全防控到气候模拟等。可以预见的是,随着深度学习技术和这一波“猫”“狗”AI工程的野蛮生长,人类正在大踏步迈入人工智能时代。
2.阿尔法狗vs.人工智能阿波罗计划
2016年第一次人机大战开始之前,笔者当时做了一个简要的论述:“在我看来,本次人机大战,机器智能战胜高智商人类的可能性极大!在不远的将来,人类有限的感知计算在拥有超级强大计算资源并结合智能算法的机器面前将不堪一击。同时,这次人机大战也是对大数据深度学习技术的一次实战检验。为什么这样讲,虽说博弈搜索技术已在国际象棋的对弈中取得了巨大的成功,但却难以适用于围棋,因为围棋棋盘横竖各有19条线,共有361个落子点,双方交替落子,这意味着围棋总共可能有10^171(1后面有171个零)种可能性,这个数字到底有多大,我们宇宙中的原子总数是10^80(1后面80个零,这个估算数据来源于网络,无法确认)。就是说穷尽整个宇宙的原子数也不能存下围棋的所有可能性 。另外,从搜索树的分枝数看,国际象棋约为35,如果只构造分析7步棋的博弈搜索树,则只需甄别35^7≈650*10^8种变化,这对每秒计算2亿步棋的“深蓝”计算机而言,想一步棋约需5分钟。而围棋的分枝数约为200,若也分析7步棋的变化,则要计算200^7个结果,想一步棋则需2年时间。”下面是国际象棋和围棋的计算复杂度比较示意图。


图3 象棋和围棋计算复杂度示意图
从上面两种博弈的计算复杂度比较图可以看出,围棋变化的复杂度要比国际象棋高得多,对围棋进行全局博弈的穷举式搜索,就传统的计算机处理技术来讲显然是不可能实现的。所以说围棋的挑战被称为人工智能领域的“阿波罗计划”,宇宙原子数都不能穷尽的可能性,机器不可能穷举哪怕少部分比例的围棋走法,机器要下赢围棋没有什么套路可言,唯一的办法就是学会“学习”,自我学习,而不能靠死记硬背。那阿尔法狗为什么会在短短几年时间内就能进行学习,并超越人类顶尖棋手的智慧呢?下文就要来说说狗的核心技术-深度学习和强化学习。
 图4 人工智能的阿波罗计划
图4 人工智能的阿波罗计划
3.阿尔法狗的类脑学习方法
一般来讲,机器学习分为监督学习(需要老师教)、无监督学习(不需要老师教)和半监督学习(自我学习和老师指导结合),而AlphaGo用到的强化学习技术就有点类似半监督学习。在笔者看来,阿尔法狗基于深度学习+强化学习+蒙特卡洛树决策的组合式学习方法(或者说学习框架)可能已经站在了人类大脑学习的门口,为什么这样讲,我们来看看阿尔法狗的系统架构。AlphaGo不是一个预编程的围棋程序,而是采用了与人类学习类似的机制,用到的核心技术如下图(分析得十分详细,感谢微软亚洲研究院郑宇和张钧波两位作者)。
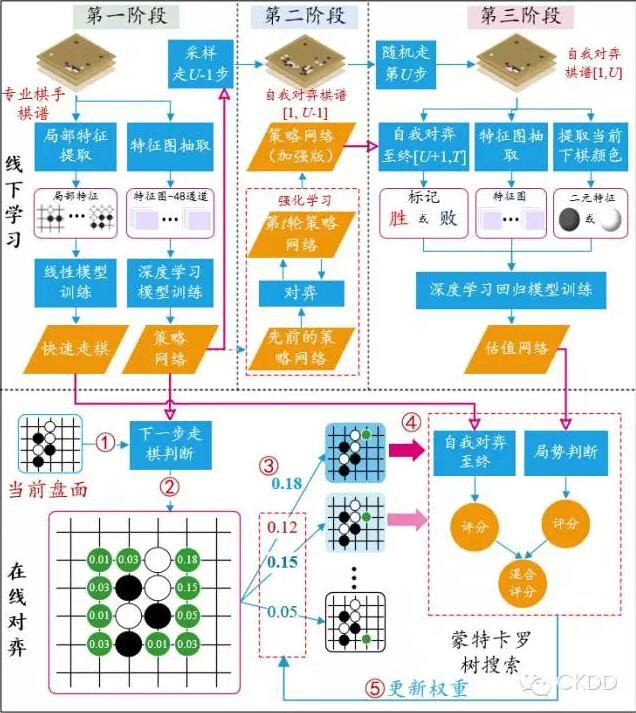 图5 AlphaGo原理图 (作者,郑宇、张钧波,微软亚洲研究院)
图5 AlphaGo原理图 (作者,郑宇、张钧波,微软亚洲研究院)
人类下棋的思维方式,一般是根据输入的局面,进行候选招法和形势判断,综合比较以后给出最终落子策略。AlphaGo的学习方法与此非常相似,从上面架构图分析可以看出,阿尔法狗的学习分为三个阶段进行:
(1)基础学习阶段-通过对棋谱的深度学习完成策略网络的构建,直接使用人类高手的落子弈法(也就是棋谱),采用深度学习技术训练一种有监督学习型走棋策略网络。这个策略网络能对走子时的弈法快速采样,用来预测一个局面数据集中人类棋手的落子情况。AlphaGo的策略网络,就对应了人类“选点”决策过程,选点决策要基于我们历史的学习情况,老师的指导情况,来决定其掌握的基础博弈水平。这个过程在于快速的学习历史棋盘,获取较优的下棋选择,类似于我们的观察学习获得的第一反应,准确度不高所以我称之为基础学习。
(2)提升强化阶段-通过自我对战强化学习来提高博弈水平,采用强化学习技术来优化先前的走棋策略网络,通过自我博弈的强化学习迭代结果,来提升前面的策略网络。此阶段是将该策略调校到赢取比赛的正确目标上,而非最大程度的预测准确性。强化学习对前一版策略网络用策略梯度学习来最大化该结果(即赢得更多的比赛),通过和这个策略网络自我博弈,即与之前的“自己”不间断训练以提高下棋的水平,这个过程有点类似于人类的巩固学习和理解贯通阶段。
(3)实时决策阶段-通过深度回归学习构建估值网络,用来预测自我博弈强化学习数据集里局面的预期结果,即预测那个策略网络的局面会成为赢家。结合蒙特卡洛树(MCTS)搜索压缩搜索空间,降低了搜索时间复杂度, MCTS决策有效结合了策略网络和估值网络,形成了完整的决策系统,利用强化学习对整个盘面的全局输赢概率进行判断,类似于人类的判断决策过程。
上述三个阶段还分为线下和线上两个部分,线下学习类似于我们打基础,巩固复习阶段,在线学习是考试决策阶段。这三个阶段的核心关键词是模仿,而不是规则。这点很重要,基础学习阶段靠对历史棋盘的深度学习进行模仿,获得初始知识,强化学习自我对战也是模仿逐步形成自己的决策判断,这也是为什么谷歌的阿尔法狗会完胜IBM的沃森,因为人类与生俱来的行为不是基于规则而是基于模仿的,通过模仿建立起基本知识体系之后,才会出现规则。从这个角度看,谷歌号称十年内实现通用人工智能,不是没有可能,因为除了强化学习之外,还有迁移学习、对抗学习、认知学习…具有强大计算能力的机器可以把人类的学习方式虐个遍,总有会找到一条有效的模仿之路。
4.阿尔法狗的深度学习架构,也许开启了机器智能的魔盒
深度学习的基本神经元模型,模拟了人脑的神经元轴突构建过程,为什么人工神经网络这个超级火箭模型几十年前就提出来了,而到现在才开始爆发出力量呢?因为受限于燃料和加速器,例如要模拟一亿个神经元。每个神经元有100万个连接,就是100万亿条计算路径,人脑有800亿个神经元,能达到人类一样计算能力的深度学习网络要能产生8万亿条计算路径。这在十年前都是无法想象的,几十年前更是没有大数据燃料,也没有超级计算加速器。而现在各大互联网巨头的服务器农场装备上了GPU的计算力,加上全球联网的大数据,所以深度学习得以爆发,这对传统机器学习技术的冲击也是巨大的,阿尔法狗的深度学习架构,也许开启了机器智能的魔盒,为什么这样讲,下面几点值得关注:
(1)大数据条件下,传统机器学习的温室模型、脆弱的人工特征工程、单模态的计算能力,难以走出实验室进行大规模应用。大数据的智能学习需要满足样本自由化和特征工程自动化处理能力,深度学习之路就是在逐步解决这一问题。
(2)阿尔法狗基于深度学习、强化学习和蒙特卡洛树决策的类脑学习架构,加上谷歌巨量的云计算和GPU资源,这种系统架构比以前的任何人工智能技术都靠谱,扩展空间巨大。早期关于动物学习的观点就是基于强化学习框架构建,每一次成功都会换来奖励,从而加强动物大脑中对这种奖励的正强化学习联系,而每一次失望都会造成相应的弱化学习行为。所以,对于成功的机器学习系统来讲,强化学习能力不容忽视,因为它们能发展出直觉和识别能力,而不只是按照程序员编好的程序工作。
(3)未来多种学习方式的深度交叉融合,将极大推进深度学习的应用价值特别是人工智能的突破。机器的情感、记忆推理等高级智能,将会由基于深度特征学习和加装存储记忆、推理模块的迁移学习、强化学习、对抗学习等各种学习方式的交叉融合而实现,未来的机器学习方式可能远不只这几种,其本质都是在模仿人类的学习方式。迁移学习代表了我们的进化过程,学习的举一反三、触类旁通,强化学习类似周伯通左右互搏,对抗学习完全是无师自通等,以深度学习为主线的技术栈极大地拓展了机器学习能力。
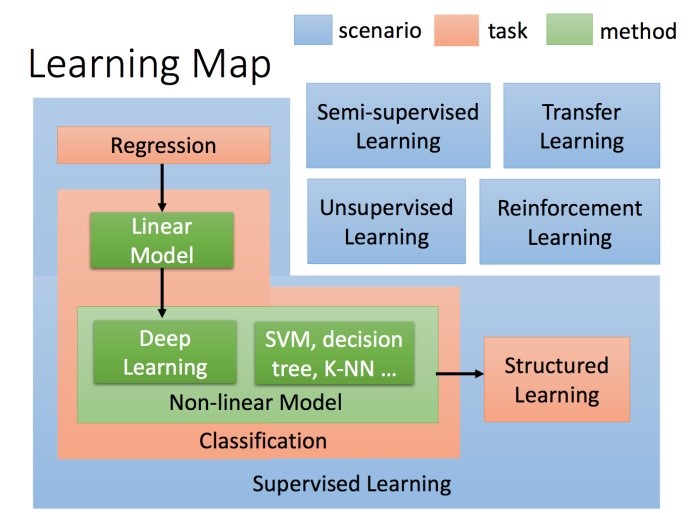 图6 机器学习分类地图
图6 机器学习分类地图
(4)通用AI之路任重道远,无监督学习是最后一座待突破的堡垒。大家都知道深度神经网络有如此神效,但具体的网络参数为什么能够表现出智能恐怕无人知晓?人的大脑分两个部分。一部分(大脑皮质)负责产生意识。一部分负责记忆、运算。深度学习算法模拟的是后者。但对于前者,人类还一无所知,类脑与神经计算科学可以说还没有真正入门,另外无监督学习能力才是真正智能诞生的基础。这方面的进展还不容乐观,深度学习四大金刚之一LeCun对AlphaGo的评价可见一斑。
LeCun说到:“绝大多数人类和动物的学习方式是非监督学习。如果智能是个蛋糕,非监督学习才是蛋糕主体,监督学习只能说是蛋糕上的糖霜奶油,而强化学习只是蛋糕上点缀的樱桃。现在我们知道如何制作“糖霜奶油”和上面的“樱桃”, 但并不知道如何制作蛋糕主体。我们必须先解决关于非监督学习的问题,才能开始考虑如何做出一个真正的AI。这还仅仅是我们所知的难题之一。更何况那些我们未知的难题呢?”正如LeCun所说,未来解码人类学习方式的重大突破性技术,很可能会由无监督学习来完成,因为无监督才是人类和动物学习的关键模式,婴幼儿通过少量有监督学习训练之后,在后续几十年的成长过程中,能够观察并发现世界的内在结构和获得经验知识,都是一种无监督的自发主动的学习模式,而不是像小时候被父母告知每项事物的名称和意义。而AlphaGo的核心技术采用了监督学习和强化学习,强化学习离无监督学习能力还很远,所以说对于完全无监督学习这个AI堡垒来讲,阿尔法狗应该说还在门口摸索,但无疑现阶段的进步也是十分巨大的。
5.弱AI到强AI的生产力变革
李开复曾提到硅谷近几年的一个趋势:“做深度学习的人工智能博士生,一毕业就能拿到200到300万美金的年收入的offer,这是有史以来没有发生过的”(估计是极个别现象)。与之相比的是,美国大学生的平均终生薪金收入是230万美金,而高中毕业生的平均终生薪金收入是130万美金,深度学习博士一年的收入是普通大学生一生的收入,可见各大科技巨头在深度学习和人工智能这个领域押下了多重的筹码,难道就不怕打水漂麽?其实是在赌一个关键节点,所谓的风口技术,我们从人类社会的发展来看,经历了农耕时代、工业时代、电气时代和当今的网络时代,现在正是跨越智能时代的关键技术节点,很大程度上就看深度学习等关键AI技术能否担当得起如蒸汽机、电灯和互联网这样重大的历史性变革技术使命。深度学习能否使机器学习更标准、更易用、更智能,同时通过数据驱动来降低机器学习技术的应用门槛,这是AI技术普及的必须条件,所以科技巨头们必须押重注争抢这一技术至高点。种种迹象表明以深度学习为代表的新型机器学习技术体系有望担此重任。
当然,AI目前的发展还处于弱AI(Artificial Narrow Intelligence ,ANI)阶段,如阿尔法狗一样只擅长某一方面的人工智能。这个阶段的AI是人类的好助手,就像电视、汽车、电脑一样为我们所用,提高我们的工作效率,如工业机器人、医疗机器人、智能问答、自动驾驶、疾病诊断、自动交易、智能终端等工具,极大提高了信息社会的生产力。而强人工智能(Artificial General Intelligence ,AGI)将在各方面相当于人类或者超过人类,也称为通用人工智能,谷歌做AlphaGo的终极目标在于此。越是强大的技术,其自身发展的速度(指数级增长)也是无法想象的,当谷歌的自动驾驶狗(已行驶超200万公里)、医疗狗(DeepMind各种疾病诊断AI已初现身手)、翻译狗(谷歌几十种语言的自动翻译)、军事狗(Boston Dynamic机器人)、金融狗…等各种狗连成一片的时候,工业机器人一定会走出牢笼,变身各种机器助手进入到你的家里和办公室里,而狗的服务端则会像电力一样提供源源不断的智能服务,强AI时代也就成为现实了,当然这个发展过程可能存在极大变数,如何防止失控和垄断?这是马斯克创立OpenAI联盟的原因,不过好像联盟里的成员也都些能搞垄断的主,都是在花巨资建设自己的AI系统。
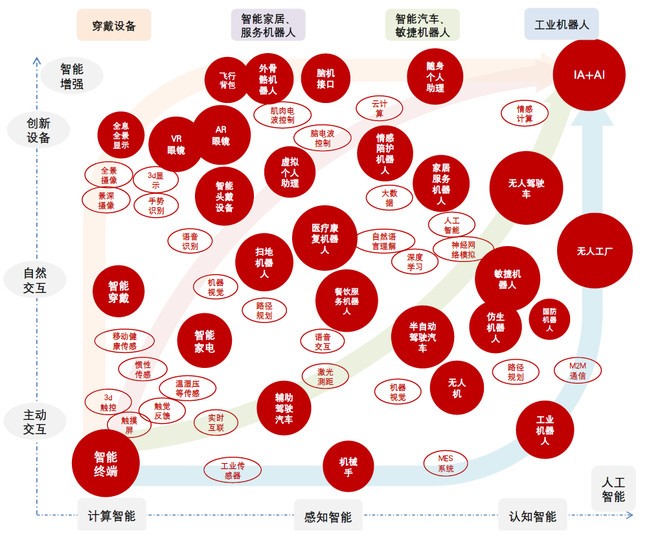 图7 人工智能的生产力变革
图7 人工智能的生产力变革
人工智能的发展速度只会越来越快,IBM的watson在有足够病例和病理知识的输入下,其对一般病症的判定准确率能高于初级医生,换句话说,它可以替代美国大多数社区医院的医生,其在律师行业也能作为助理律师处理一般性事务。比沃森智商高很多的AlphaGo发展空间更大,游戏AI,围棋AI,医疗AI,金融AI…AlphaGo架构的通用化和横向扩展并不难,深度学习、神经网络、强化学习、MCTS和GPU计算等都是通用的技术,AlphaGo的成功验证了这些技术组合的高效性和可扩展性。向其它领域扩展,核心技术和算法都是相通的,只是数据不同,服务载体和表现形式不同而已。面对各领域的智能化变革,在不远的将来,人造劳动者正在从各个领域汹涌而来,大部分蓝领或白领工作都将被取代,飞行员、司机,流水线工人,客服,翻译,医生甚至教师。唯一的变数在于艺术、创造和沟通,虽然机器现在也能作诗和画画了,但是否能够超越人类,还没有定论。
6.结论与展望
当阿尔法狗这样成长速度远超人类的智能系统,在各行各业全面开花的时候,对我们生活造成的冲击无疑是巨大的,会提高生产力,抢我们的饭碗,甚至提高整个文明的智慧水平。那很多人可能会问,“猫狗”们能产生自我意识吗?我想这个问题是决定人类命运的关键,也是如何与强AI和谐相处的关键。马斯克(Elon Musk)、盖茨和霍金都曾提出关于人工智能失控的问题,霍金称人工智能会威胁奴役人类,马斯克认为人工智能是在“召唤魔鬼”,担忧未来人工智能可能会被用于邪恶,甚至会诞生《终结者》里的“天网”系统(拥有自我意识)毁灭人类。
早在1950年,图灵的论文《计算机器与智能》(Computing Machinery and Intelligence)开篇就说到:“我提议思考这样一个问题,机器能思考吗?”,并提出了最著名的图灵测试方法。直到现在,实现图灵测试还是遥遥无期,短期来看,AI要产生自我意识很难,毕竟连自然语言处理的很多问题都还没有解决,当AI能像人类一样流畅地、富有逻辑和情感地听、说、读、写之后,再谈自我意识可能会靠谱一些。不过任何事物的发展也有个例外,当网络规模巨大、连接复杂到一定程度之后,会否产生一些变异或进化?只有科技巨头们自家的机器农场才知道,一般的研究机构因少有海量的数据资源和计算能力也就无从知晓了,毕竟我们连深度神经网络为何有如此神效都不知道,超大规模的神经网络参数调节为什么能够表现出超强的识别和学习能力?更不知道,对人类来讲,这个问题就像理解我们自己的大脑一样难。当然,正如哈萨比斯所说,信息过载和冗余是大数据时代我们面临的首要问题,我们希望能利用AI找到元解决方案,人工智能可以帮助我们更好地探索人脑的奥秘。
总之,汽车淘汰马车,电灯淘汰油灯,电脑淘汰人脑,这些个历史进程是无法改变的,我们的变革周期在加速,工作的变化也会越来越快,也许就在你觉得自己通过挑灯充电走在前面的时候,其实你掌握的技能已经处于被淘汰的边缘。如果有奇点的话,现在就正处于加速收敛的阶段,量变到质变的前夜,强人工智能将深刻改变我们生活,也会给我们带来巨大挑战。阿尔法狗的彻底胜利在昭示着AI的觉醒,强AI的诞生对于人类而言仍是吉凶莫测,一边是《星际迷航》,一边是《终结者》,路掌握在我们自己手中。
来源:点金大数据
版权声明:本站原创和会员推荐转载文章,仅供学习交流使用,不会用于任何商业用途,转载本站文章请注明来源、原文链接和作者,否则产生的任何版权纠纷与本站无关,如果有文章侵犯到原作者的权益,请您与我们联系删除或者进行授权,联系邮箱:service@datagold.com.cn。

