深度智能的崛起(三):神经网络研究的三起三落

“世界的尽头,是雄狮落泪的地方,是月亮升起的地方,是美梦诞生的地方。”——大卫《人工智能》
接上文《深度智能的崛起(二)》
♦神经元与神经网络
一直以来,我们的大脑如何从感知到的信息进行学习和判断,并形成记忆、情感和意识,这对于人工智能研究来讲仍然是一大谜题。深度学习的基础理论源于人工神经网络(Artifical Neural Network, ANN),深度学习通过逐层提取低层特征形成更加抽象的高层表示,来进行事物类别或属性特征的自动化学习,以发现数据的分布式特征表示。而早期ANN的研究动机就是通过构建类似人脑神经系统的神经网络结构,运用大量简单处理单元经广泛连接来组成人工神经网络,从而达到模拟人脑学习的目的。然而神经网络的研究与应用并不顺利,人脑是一个复杂巨系统,由1000多亿神经细胞(神经元)交织在一起的网状结构组成,从而产生了人的智能行为,要真正模拟(或者部分模仿)人脑功能是否可行现在还不得而知,不然人工智能研究六十年就不会只是当前的成绩了。
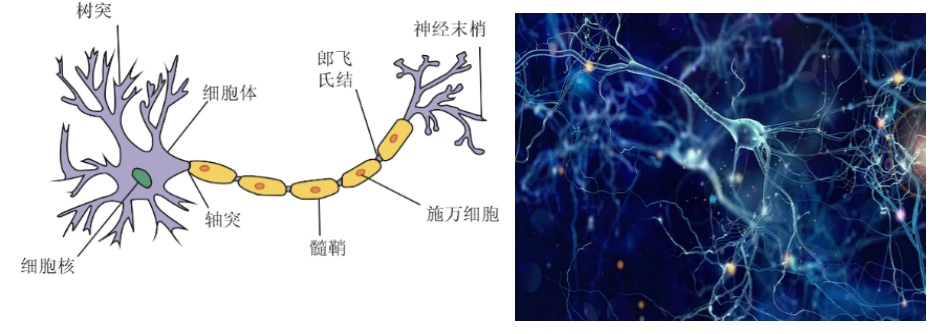
图3-1 左边是单个生物神经元结构,右边是神经元组成的生物神经网络
早在1889年Cajal就提出了神经元,他认为神经系统都是由若干结构相对独立的生物神经元构成。神经元的核心结构包括三部分:细胞体、轴突、树突,轴突作为神经元的输出,树突作为神经元的输入端。 单个神经元可以从别的神经元接受多个输入,输入神经元一般分布于不同的部位,对接收信号神经元的影响也是不相同的。所以神经元接收到的信息通常在时空维度上是复杂多变的,而且需要对这些复杂多变的输入信息进行加工整合,才能确定输出何种强度的激活信息。基于这种加工机制,神经系统中数以亿计的神经元才能有序协同处理各种复杂的接收数据。
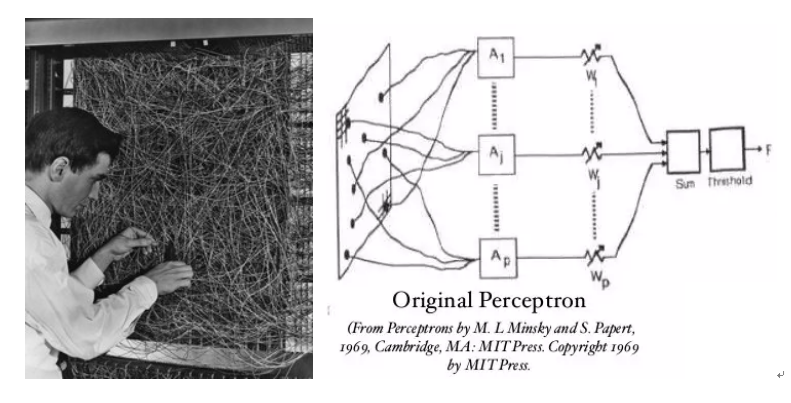
图3-2 左边为Rosenblatt的物理感知机,右边为感知器系统结构,也是第一个人工神经网络原型
1943年,心理学家McCulloch和数学家Pitts才设计出第一个神经元的数学表达MP模型,成为后来大多数神经网络的基础单元。在1958年,美国学者弗兰克·罗森布拉特(Frank Rosenblatt)首次提出了第一个神经网络的原型(如图3-2),被称为感知器(Perceptron),感知器也被指为单层的人工神经网络,以区别于较复杂的多层感知器(Multilayer Perceptron)。感知器是一种最简单的人工神经网络,尽管结构简单,但却能够学习并解决相当复杂的问题,而且第一次引入了学习的概念,使得神经网络成为当时的研究热点。
♦神经网络研究的“三起两落”
笔者在10年前对神经网络和支持向量机两个机器学习方向都有过粗浅的学习和了解,见证了以支持向量机为代表的浅层学习技术的火爆,但却始终少有看到机器学习技术真正走出实验室,并落地应用。直到最近几年,神经网络换马甲为深度学习后一鸣惊人,使得机器学习领域这几十年来积累的成果,得以逐渐走出实验室,在学术界和产业界引起了强烈的反响。但神经网络的复出却并不那么容易,下面我们就来看看人工神经网络发展历程中的“三起两落”(如图3-3)。
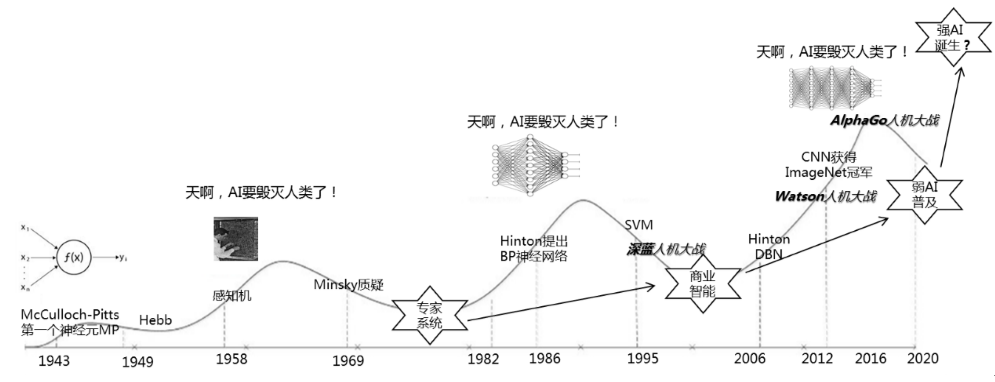
图3-3 神经网络的三起三落
其实神经网络的研究最早可以追溯到20世纪40年代,1943年,心理学家McCulloch和数学家Pitts设计出MP模型,作为大多数神经网络的基础单元,1958年,Rosenblatt提出了第一个神经网络的原型-感知器,引发了AI研究的一次热潮。然而好景不长,感知器最初被寄予厚望,但在1969年AI先驱Marvin Minsky指出了以感知器为代表的单层神经网络的局限,并证明其甚至无法解决简单的异或(XOR)等线性不可分问题,导致了后来人工神经网络研究的第一个低潮,低潮期人们选择了更折中的应用方案,专家系统的应用和研究应运而生。
直到1986年,Hinton和Williams提出了反向传播(BP)算法,使得大家认识到多层神经网络并没有单层神经网络的缺陷,而且BP算法能对较少层数的神经网络进行有效地训练,尽管新方法也存在严重的问题,但在当时的条件下,能缓慢、低效地学习已经很不容易了,神经网络研究第二次兴起。但BP算法也有缺陷,基于梯度下降法的问题求解容易陷入局部极小,当网络层数加深后会导致梯度消失(爆炸)问题,没有大规模数据进行学习的过拟合问题,即使有大量数据,当时的计算能力也不足支撑深度网络的训练等等。随着1995年支持向量机(Support Vector Machines, SVM)的提出,神经网络研究第二次进入冰河期。这次AI研究的冰河期人们还是选择了切实的应用方案,基于数据仓库和OLAP数据挖掘的商业智能应用逐步兴起。这个时期,1997年IBM的深蓝人机大战世人瞩目。
再到2006年,Hinton提出了DBN,通过逐层预训练方法解决了深度网络的训练难题[4],神经网络研究第三次兴起,只是这次Hinton给多层神经网络换了个马甲,改称深度神经网络(即深度学习)。这个时候,我们已经拥有了巨大的计算能力,以及遍布互联网、移动互联网和物联网中的海量大数据,后来证明这两个条件对于深度神经网络的有效运行至关重要。六年后也就是2012年,ImageNET图像识别大赛[5],Hinton带领的深度学习团队一鸣惊人获得冠军,应用效果远超传统方法,从而开启了深度学习的寒武纪大爆发,各种拓展基于深度思想的多层神经网络结构层出不穷,引领了工业界人工智能应用研究的热潮。这个时期,2011年IBM沃森人机大战挑战智力问答冠军,也引起了极大关注。
2016年AlphaGo人机大战就不用多讲了,媒体的报道实在太多。2016年,2017年可以说是以深度学习为代表的AI研究应用顶峰。
♦深度学习一小步,人工智能的一大步
上述分析表明,神经网络发展已经历的三起两落,代表了人工智能研究应用的两次泡沫期,这给过分热衷深度学习技术与人工智能研究应用的人来讲,是一个警示,深度学习是否会陷入瓶颈期,导致神经网络的三起三落,暂时还没有定论。但期望越大,失望越大,毕竟深度学习技术没有想象中的那么强大,至少在智能算法层面的突破还很有限(主要靠的还是大数据和计算力)。换个角度看,深度炼丹术的兴起,会不会是因为机器学习研究几十年来在工程应用落地方面迟迟无重大进展,神经网络算法的一点小改进(正好遇到了大数据与GPU)就被当做了救命稻草? 或者说即使神经网络的深度架构碰巧模拟到了人类视觉皮层学习机制,但我们能全面解码人脑学习吗?从神经科学研究进展来看,短期内十分困难。
不过值得肯定的是,深度学习的这一小步也许代表了人工智能发展的一大步,现在正处于AI技术和产业发展的波峰。而这一热潮的兴起一是得益于深度学习的突破,二是互联网、物联网和移动物联网等技术促使大数据的爆炸式增长成为常态。三是大数据分析预测是解决不确定性问题的必然,大数据条件下的问题复杂性,越来越难以应用传统建模技术和浅层机器学习方法加以解决,深度学习的诞生和发展正逢其时。笔者认为接下来,不管是深度学习持续发展还是又陷入一次AI冰河期,弱AI的普及应用是毫无疑问的。从专家系统到商业智能,从商业智能到弱AI的普及,趋势很明显(如图3-3),每次AI研究的低潮必有相应的行业应用成果诞生。
从人工智能发展历程来看,科学研究的重大突破,就像DNA双螺旋结构一样呈螺旋形上升发展,不可能一蹴而就。而每一次科学研究和应用的重大进步,往往是最先由个别领军人物点破,才促使其他同行蜂拥而至而成为研究热点,进而在短时间内做出大量更具突破性的成果,并应用落地带来相关产业界的发展。笔者认为,人工神经网络能够在换马甲为深度学习后成功逆袭,正是人工智能和机器学习领域几十年来积累诞生的科学研究和工程应用成果,虽然当前深度学习被看作是通向人工智能的关键技术,被寄予厚望,但也引起了不少行业领军人物的担忧。如深度学习之父Hinton就提出了反向传播的局限性,并宣称应该重新设计神经网络的训练方法[6],国内的机器学习专家周志华也对深度学习热潮进行了冷思考。
未完待续…
来源:点金大数据
版权声明:本站原创和会员推荐转载文章,仅供学习交流使用,不会用于任何商业用途,转载本站文章请注明来源、原文链接和作者,否则产生的任何版权纠纷与本站无关,如果有文章侵犯到原作者的权益,请您与我们联系删除或者进行授权,联系邮箱:service@datagold.com.cn。

