沃森(Watson)认知智能探秘:大象还能起舞吗?
 蓝色巨人IBM无疑是世界上最大的IT公司之一,从硬件到软件,从行业解决方案到大数据、人工智能产品,曾经头上光环无数。不过俗话说“花无百日红,人无千日好”,IBM这些年的路也是走得越来越艰难,去IOE蓝色巨人首当其冲(IBM,Oracle,EMC),还时刻面临着互联网巨头的挑战,以至于多年前就有不少专家在唱衰IBM,技术服务实力不够,产品性价比低,反正就是在加速没落。大象还能起舞吗?笔者表示很难回答,但IBM有个镇司之宝值得一说,那就是沃森(Watson),2011 年Watson一举击败两位人类选手,获得全美智力挑战赛 Jeopardy(危险边缘) 的冠军,成为继1997年超级电脑深蓝(DeepBlue)战胜国际象棋大师卡斯帕罗夫后的又一次人机大战。在比赛中,Watson展示出了超强的自然语言理解能力。本文就来探秘蓝色巨人的家底之一-“沃森(Watson)”认知智能。
蓝色巨人IBM无疑是世界上最大的IT公司之一,从硬件到软件,从行业解决方案到大数据、人工智能产品,曾经头上光环无数。不过俗话说“花无百日红,人无千日好”,IBM这些年的路也是走得越来越艰难,去IOE蓝色巨人首当其冲(IBM,Oracle,EMC),还时刻面临着互联网巨头的挑战,以至于多年前就有不少专家在唱衰IBM,技术服务实力不够,产品性价比低,反正就是在加速没落。大象还能起舞吗?笔者表示很难回答,但IBM有个镇司之宝值得一说,那就是沃森(Watson),2011 年Watson一举击败两位人类选手,获得全美智力挑战赛 Jeopardy(危险边缘) 的冠军,成为继1997年超级电脑深蓝(DeepBlue)战胜国际象棋大师卡斯帕罗夫后的又一次人机大战。在比赛中,Watson展示出了超强的自然语言理解能力。本文就来探秘蓝色巨人的家底之一-“沃森(Watson)”认知智能。
1.沃森(Watson)源起
沃森(Watson)以IBM的首位CEO,Thomas J. Watson命名,是IBM大力推广的认知智能解决方案和系统。2011年Watson一举击败人类顶尖选手,获得全美智力挑战赛“Jeopardy(危险边缘)“冠军,从此名声大噪。Watson的起源,得从15年前说起,自从1997年深蓝电脑(DeepBlue)战胜国际象棋大师卡斯帕罗夫之后,IBM一直憋足劲在寻找一个新的挑战,准备再次大显身手。其中Charles Lickel(IBM的研发经理)某天在食堂吃饭时,注意到了同事们对智力挑战赛Jeopardy的热烈关注,顿时想到,为什么不能研发一个机器人参加这个全国闻名的竞赛呢?我们都知道这种智力抢答竞赛,需要极快的反应能力(秒级)和海量的知识存储、记忆、检索能力(智力问答涉及广泛的知识领域),在当时,Charles Lickel的这个想法被很多人认为是不可能实现的,这需要突破自然语言理解这一AI技术瓶颈。计算机可以在棋类游戏中击败人类,是因为下棋一般具有明确的规则,通过加强计算能力始终能找到有限的、可行的解;但现实世界中的自然语言和知识问答却有着不规则、不确定的复杂性,数据一般是非结构化的,语义结构的多样,问题不明确,还面临回答匹配评价的不确定性等等问题。总之,机器需要从海量的人类语言知识体系或语料库中快速找出确切的答案,特别是涉及语义挖掘层面,绝非易事。但辛亏Charles Lickel这一想法得到了他所在部门领导的肯定和支持。
2006年,Watson第一个内测版面世,在智力竞赛测试中只有15%的回答准确率,而人类选手回答正确率是85%。同年,还有两件大事值得同表。也是2006年,阿尔法狗的缔造者,正在攻读博士的黄士杰(Shih-Chieh Huang)独自开发出了第一款围棋程序(2014阿尔法狗项目才正式启动),并命名为AjaGo,当时的开发团队只有三个人:哈萨比斯、席尔瓦、黄士杰,哈萨比斯是谷歌DeepMind公司的老板,席尔瓦是黄士杰的经理,也就是说,阿尔法狗初期团队主力干活的是一位华人。也是2006年,深度学习之父Hinton在Science上发表了一篇论文,利用单层的RBM自编码预训练方法,使得深度神经网络的训练变得可能,开启了深度学习时代,并在2012年的ImageNet大赛夺冠,从此掀起了AI研究与应用的热潮。
 图1 深蓝人机大战
图1 深蓝人机大战
2.沃森的智能成绩单
用IBM官方的宣传语讲[3]:沃森能在不到三秒钟的时间里对海量语料库挖地三尺,在长达数亿页的资料里展开搜索,通过集成大量的自然语言处理技术产生候选答案,再快速对候选答案进行各种维度的评价和评分。这个过程需要大量的计算,开发的100多套算法可以快速响应和解析问题,检索海量信息然后再筛选出答案。这种深度问答系统的核心技术是基于自然语言理解的认知挖掘,也就是IBM和一些专家大力宣传的的认知智能。下面来看看Watson从2006年诞生至今的智能成绩单[5]:
1)2006年,Watson第一个测试版本面世,在智力竞赛内部测试中只有15%的回答准确率,回答一道题要花费数小时。
2)2008年,通过两阶段学习和并行计算优化,大幅提高问题回答的准确率和响应效率,Watson开发团队增加到数十人。
3)2011年,Watson参加智能挑战赛“危险边缘(Jeopardy)”,这是该节目有史以来第一次人与机器对决。Watson打败人类记录保持者,成为冠军并获得100万美元奖金。
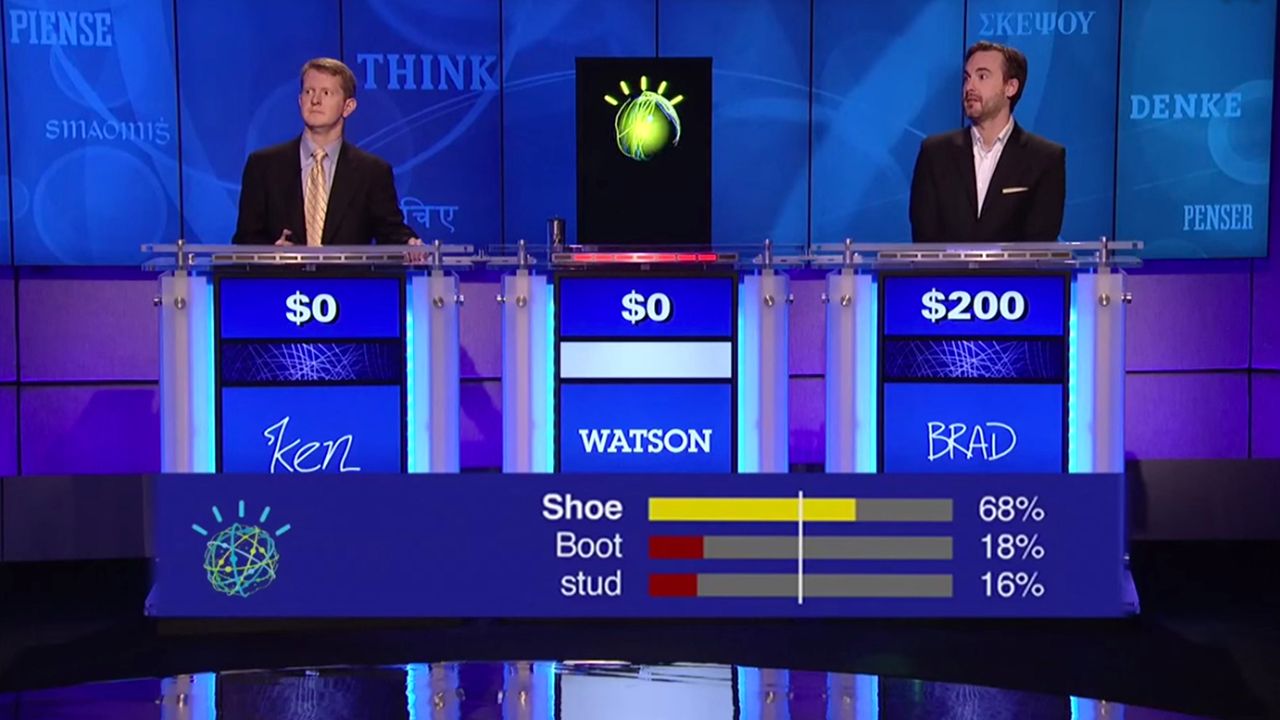 图2 沃森人机大战
图2 沃森人机大战
4)2012-2014年,IBM成立Watson集团,并与克利夫兰医院合作挑战医疗大数据,让肿瘤专家开始使用 Watson 去分析基因数据和医疗诊断数据之间的关系,以完善个性化的治疗方案。并宣称,东京大学的研究者利用 Watson 成功治愈了一个 60 岁的白血病患者,其做法就是将该病人的基因数据与数以万计的医疗文献做对比,形成针对该患者的定制医疗方案。
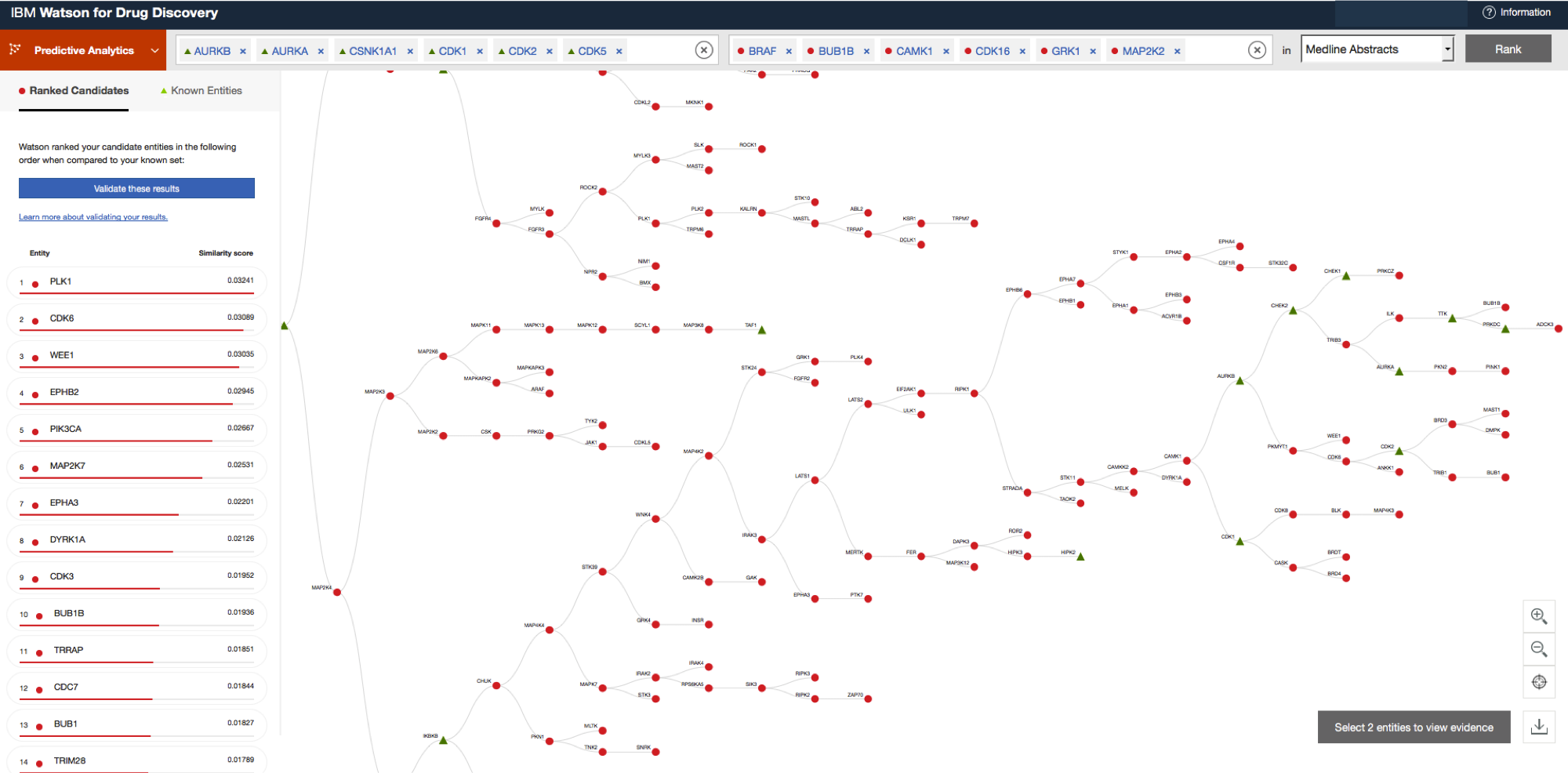
图3 Waston辅助药物设计发现
5)2015 年,Watson紧跟当下人工智能前沿发展趋势,计划为 Watson 加入深度学习技术,比如翻译、语音文本的互转等等。早期自然语言处理与大规模数据集的分析技术,拓展了深度学习技术的使用。
6)2016年,以Watson集团为中心,通过密集收购相关企业,大力拓展各行业数据智能解决方案业务。比如收购医疗成像和数据分析公司Explorys、交易欺诈公司Iris Analytics,云端医疗数据存储公司Truven Health Analytics,天气数据分析公司The Weather Company等等。
通过上述技术发展,和行业数据整合,沃森逐步在各行业数据智能分析领域站稳脚跟,以Watson为核心的沃森集团,涉足医疗健康、法律、农业、金融、教育、保险、市场营销、人力资源等多个领域。特别在医疗领域的进展喜人,与全球很多的知名医院展开合作,在中国就有20多家三甲医院。虽然也有挫折,比如和著名医疗机构德克萨斯大学附属癌症中心(MD Anderson Cancer Center)项目合作的失败。但不可否认,面对整个科技行业都在大力转型人工智能的趋势,Watson作为IBM抢占人工智能最高点的杀手锏,未来的应用潜力还是很大的。
3. 认知智能与自然语言理解
最近几年,IBM大推“认知智能”,可以说是继“智慧地球”之后的一次重大战略转型,凸显了沃森在IBM未来的核心战略地位。那什么是认知智能呢,我在前文《深度智能的崛起》[12]中有谈到,一般来讲,传统的符号逻辑方法及一般的统计机器学习方法以科学运算、逻辑处理、统计分析和规则式AI、专家系统等为核心,很难称得上智能,人工智能要真正走向智能,认知是关键,需要从如下三个层次进行突破(如下图):
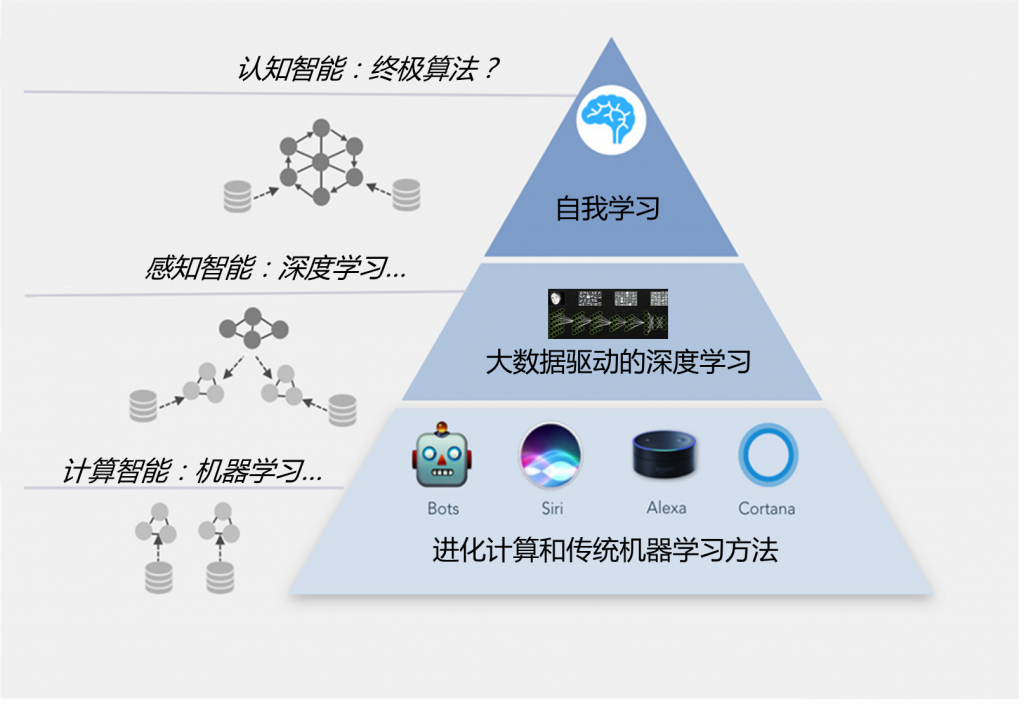
图4 人工智能的三个层次
(1)计算智能:计算智能的概念由IEEE神经网络学会于1990年提出,通常是指计算机从数据或实验观察中学习特定任务的能力,计算智能是借鉴自然进化等计算方法(如仿生类算法:遗传算法、蚁群算法、DNA计算等,还有如神经网络算法,这些算法也可以看作是数据挖掘,机器学习和人工智能部分支撑技术)以解决复杂的问题。这种方法接近于人的推理方式,即使用不精确和不完整的知识,并能够以自适应的方式产生控制行为,比如使计算机能够理解自然语言的模糊逻辑,使系统通过像生物一样学习数据中的经验和模式。
(2)感知智能:感知智能就是要使机器具有视觉、听觉、触觉等感知能力。这离不开机器学习,所有机器学习方法都是关于从数据中识别出趋势,或者识别数据所适用的类别,以便在提供新的数据时,可以做出适当的预测。通过这种学习方式,能初步让机器“看”懂与“听”懂,并据此辅助人类高效地完成如图像识别、语音识别、语言翻译等工作。近年来,以深度学习为核心的机器学习方法取得重大突破和进展,使得机器的感知智能水平正在逐步接近或超过人类,AI当前的研究应用水平就处于这一阶段。
(3)认知智能:相比感知,认知智能更进一步,能初步掌握人类一样的理解、情感和交互能力。旨在让机器学会主动思考、决策及行动,以实现全面辅助或替代人类工作。认知智能具有自适应性,及能随着目标和需求进行自适应变化;交互性,能与外部参与者进行流畅互动和交流;迭代性,能通过反馈、记忆等升级优化自己的能力;最后一点要有对环境的理解能力,比如初步认识和理解所出的世界,对语言交流的环境理解等等。要实现认知智能绝非易事,必须解决机器非监督学习问题,技术难度很大,长期以来进展缓慢。认知智能也会用到各种机器学习技术,但只要机器学习方法是不够的,如何实现记忆、情感和复杂知识推理等,要么需要终极算法的支持,要么是集成多个高级AI子系统的一整套架构协同工作。在这个层面,AI的研究还处于相当初级的水平。
而IBM沃森现阶段的认知智能水平,笔者认为还比较初级,Watson的认知特指机器通过与人的自然语言交流及不断从大规模语料库中学习,使机器更好地从海量语料数据中获得深入洞察,从而辅助人类做出更精准的决策。驱动沃森的核心技术之一是自然语言理解。我们再来看看什么是自然语言理解。对机器来讲,我们把语言分为两个大类,一是自然语言:人类交流的语言,口语、书面语、文本等,特指人类交流用语;二是人造语言:机器语言,如汇编,C++, Java,Python等,是人类设计出来的供机器使用的语言。自然语言理解主要研究如何使计算机能够理解和生成自然语言。自然语言理解既是人工智能研究较早的一个领域,同时也是计算机智能化的一个必备特征。到目前为止的人类知识有80%以上使用自然语言文字记载下来的。将来用计算机语言形式记载和处理的知识将会越来越多,比如自动问答、提取材料摘要、自动语言生成、不同语言翻译、信息检索搜索、自动语音识别等等。
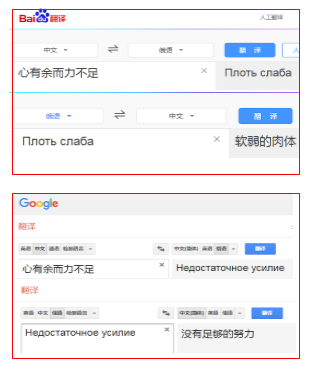 图5 机器翻译的瓶颈
图5 机器翻译的瓶颈
作为AI的关键研究领域,自然语言理解面临的复杂的技术挑战,比如图灵在50年底就提出了著名的图灵测试,就是力图解决机器的语言理解问题,相比较人工智能其它领域,自然语言理解是难度最大,进展最慢的,至今为止还未能达到期望的水平。其研究目标是建立足够精确的语言模型使计算机通过编程来完成自然语言的相关任务。如:听、读、写、说,释义,翻译,回答问题等。传统AI方法有基于规则的语言模型,如词法、语法和文法分析等,当前大规模语料库流行的时代,基于统计推理和深度学习的方法越来越重要。
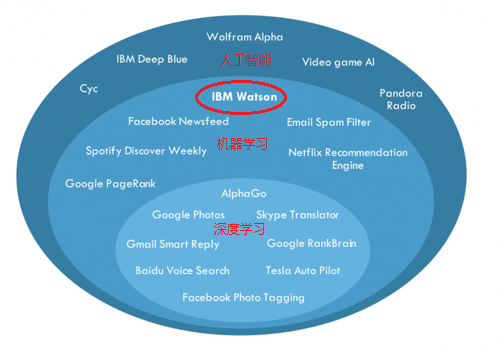 图6 Watson认知智能技术范畴
图6 Watson认知智能技术范畴
沃森的认知智能处于什么样一个技术层面呢,我们简单回顾一下AI技术三个范畴:首先是传统的人工智能技术,定义广泛,涵盖所有可能的模拟智力的方法,那时候研究人员还不清楚什么技术最有可能胜出,所以任何一本人工智能教材都可谓是一锅大杂烩,列出了智能技术相关的方方面面。其次是人工智能的一个子集机器学习,它使用数据和经验自动调整算法,成为基于规则AI之后的一种新的学习范式。再就是机器学习的一个子集深度学习,这里我就不做赘述了,前文有很多介绍。Watson的核心技术应该说是基于海量的语料库数据+统计推理结合规则式AI方法+少量机器学习方法的组合体(如上图)。接下来我们就来一探沃森技术的究竟,看看其认知智能平台架构和关键技术到底涉及哪些内容。
4. 沃森的认知智能架构与关键技术
简单来讲,Watson是一个基于深度问答技术的自然语言理解系统,依托海量语料库数据的组织和检索,加上大量统计推理算法和机器学习训练的组合。这就像若干专家系统的组合,整个系统由许多较小的功能组件组成,一个组件代表了一个子领域的专家,专注于解决一个特定的子问题。平台核心是机器阅读和理解,从自然语料库中半自动地获取知识,并将统计推理、规则方法与知识相结合。这种架构也是传统AI要进化为智能机器的经典思路,不过在李飞飞高徒andrej karpathy(现为Tesla AI部门总监)看来,这条路是不可行的。
(1)Watson认知智能架构
我们首先从软件角度,来分析Watson的认知理解过程(参考维基百科[3,6]):“在Watson分析问题并确定最佳解答的过程中,运用了自然语言处理、信息检索、知识表示推理和机器学习技术。Watson基于DeepQA技术框架,来生成假设、收集大量证据、并进行分析和评估。Watson通过加载数以百万计的文件,包括字典、百科全书、网页主题分类、宗教典籍、小说、戏剧和其他资料,来构建它的知识体系。与搜索引擎不同,用户可以用自然语言向Watson提出问题,Watson则能够反馈精确的答案。从解答的过程来看,Watson通过使用数以百计的算法,而非单一算法,来搜索问题的候选答案、并对每个答案进行评估打分,同时为每个候选答案收集其他支持材料,并使用复杂的自然语言处理技术深度评估获得的初步答案和证据。当越来越多的算法运算的结果聚焦到某一个答案时,这个答案的可信度就会越高。Watson会衡量每个候选答案的支持证据,来确认最佳的选择及其可信度。当这个答案的可信度达到一定的水平时,Watson就会将它作为最佳答案呈现出来“。整个平台架构如下图。
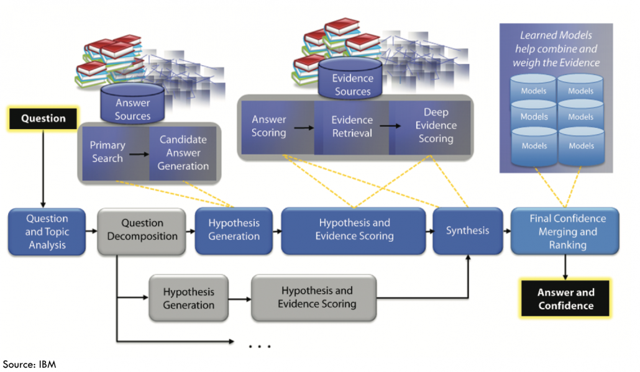 图7 Watson认知智能平台架构
图7 Watson认知智能平台架构
其中包含三个层面的核心技术:
1)对问题和语料库数据的理解:通过自然语言理解技术,基于结构化与非结构化数据处理能力,与用户的问题进行交互,并理解和应对用户的问题。这里面的核心技术是自然语言处理引擎,通过将问题解析为单词来加以理解,并映射单词之间的关系(如图8)。
2)基于假设和证据的推理:Watson具有简单的逻辑思考能力,首先像搜索引擎一样搜索海量语料库,筛选非结构化数据,如维基百科和新闻,以及结构化数据库(如病例库)数据,通过假设生成,透过数据揭示洞察、模式和关系。根据关键词检索或本体逻辑匹配技术,将散落在语料库中各处的知识片段连接起来,产生潜在的答案之后,沃森还需要搜索更多的证据,通过证据提供的新的信息,来评价答案的正确性,并消除弱的答案。通过一系列推理、分析、对比、归纳、总结和论证,来获取答案决策。
3)学习和训练:能够从海量语料库数据中快速提取关键信息,存储相关模型和中间数据库,像人类一样进行认知学习。通过学习算法训练,并在交互中通过经验学习来获取反馈并优化模型,从而提高知识理解水平。
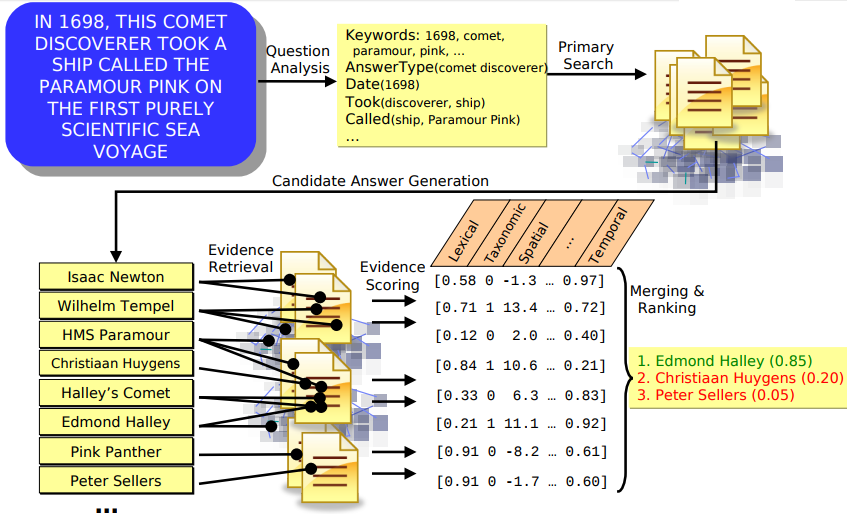 图8 Watson认知过程解析
图8 Watson认知过程解析
为什么Watson能从刚开始数小时回答一个问题,降到2-3秒回答,这就需要并行计算的支持。基于UIMA非结构化信息管理框架的Watson平台架构十分有利于并行化,整个系统由许多较小的功能组件组成,一个组件代表了一个子领域的专家,专注于解决一个特定的子问题,通过其子问题的大规模并行计算能极大提高整个系统的响应效率。其服务器集群如下图,详细硬件配置大家可以做个了解,网上官方公布的参考数据是[3,6]:“Watson由90台IBM服务器、360个计算机芯片驱动组成,拥有15TB内存、2880个处理器、每秒可进行80万亿次运算。这些服务器均采用Linux操作系统,配置的处理器是Power7系列,这是当前RISC(精简指令集计算机)架构中最强的处理器,拥有8核、32个线程,主频最高可达4.1GHz。”
 图9 Watson服务器集群
图9 Watson服务器集群
(2)深度问答(DeepQA)技术
对上面的认知智能平台架构进行细化,可以得到下图,IBM称之为DeepQA即深度问答技术架构。首先我们通过一个例子来看其深度问答是怎么样一个过程[3]:比如要回答“《星球大战》的导演是谁?”这个问题。Watson通过摄像头识别文本来输入这个问题,先分析这个问的是人,然后再细化到是一位导演。接着分析《星球大战》,会从海量的语料数据库中找到很多文章。它要定位某篇文章,其中把星球大战的导演那一段找出来,然后对这一段做深度分析,比如找到一句话,这句话里说到这是某人在哪一年执导(direct)的,但没有提导演(director)这个词。实际上还可以找到很多类似的词,它就需要过滤,它先会找人名,比如斯皮尔伯格、卢卡斯等,这些都是潜在答案。针对这些答案它要找相关的证据去支持。它会再把“星球大战”和“斯皮尔伯格”一起搜索,或者是和“卢卡斯”搜索,结果发现“星球大战”和“斯皮尔伯格”共同出现在同一篇文章中比较少,而“卢卡斯”比较多。但是这还不是一个足够强的证据,还要列出证据一、证据二、证据三、证据四是什么。下一阶段是对于卢卡斯和斯皮尔伯格做快速排序,通过一个模型来确定哪个应该排在前面,哪个应该排在后面。沃森就要根据过去的比赛和知识库来确定。最后它得出的答案是‘卢卡斯’。
 图10 Watson问答分析流程[3]
图10 Watson问答分析流程[3]
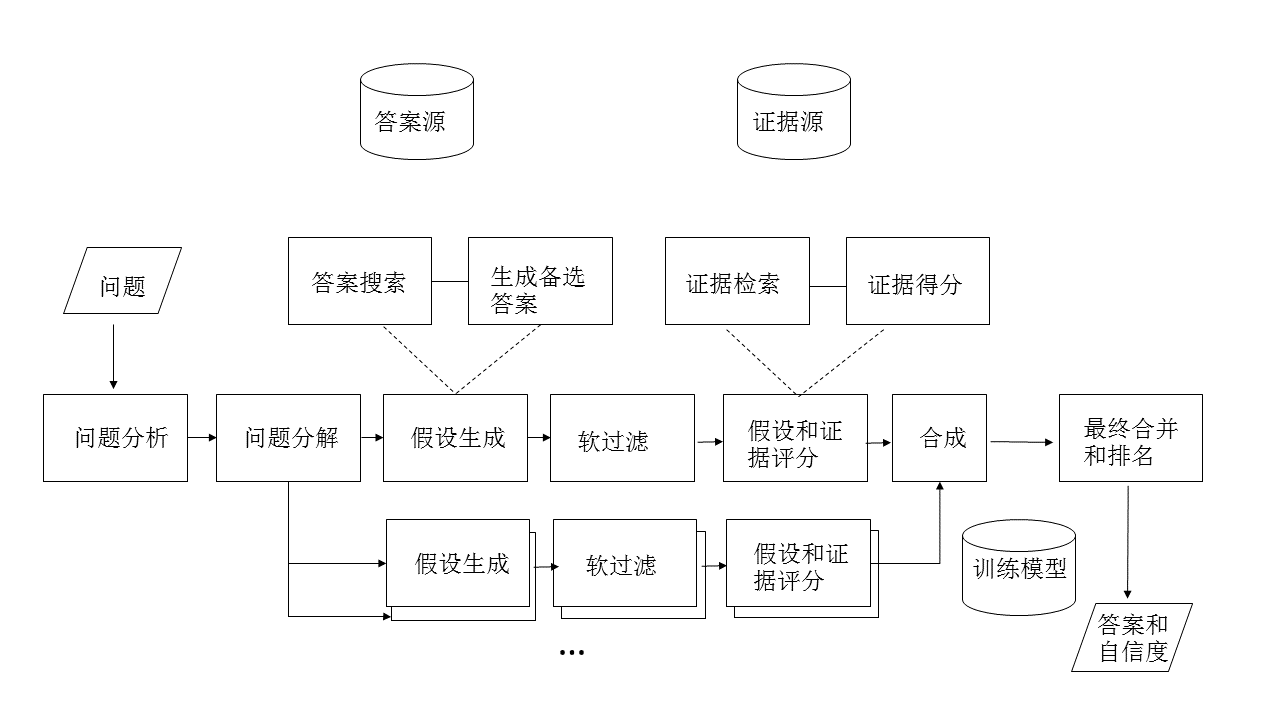 图11 Watson问答分析流程[4]
图11 Watson问答分析流程[4]
从上述过程分析可以看到,深度问答不只是简单的搜索引擎关键词匹配,而是有一列的答案抽取和证据评分算法的支持,从某种程度上讲,这是一种深关联挖掘分析技术,再配以知识库、本体和语义网络等技术的使用,应该说Watson的知识存储、记忆和学习等方面能力还有大幅提升的空间。根据DeepQA研发团队在AI Magazine上的公布论文《Building Watson: An Overview of the DeepQA Project》和其它相关信息内容,能得出如下细化的DeepQA系统技术架构[4]。
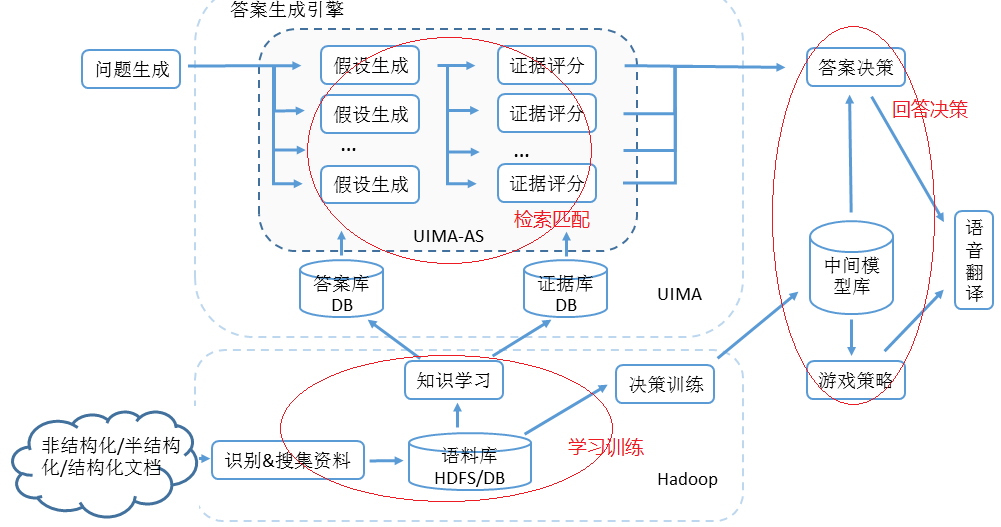
图12 Watson DeepQA技术架构[4]
从整个技术架构来看,DeepQA包括如下三个关键部分。
一是语料库的收集存储和学习训练:海量语料库是决定自然语言理解的关键,Watson语料的来源十分广泛,不仅有互联网网页这样的非结构化知识源,也有结构化知识源,如百科全书、小说或业务数据库,还有对文本、图片等半结构化数据等等。通过Hadoop的MapReduce等并行计算框架进行初步的大数据分析,并生成UIMA框架下的统一信息结构,提供上层检索和利用。
二是通过基于答案和证据智能检索匹配的问题理解和关联分析:沃森通过一系列自然语言理解技术完成这一部分工作,包括语法语义分析、对各个知识库进行搜索、提取备选答案、对备选答案证据的搜寻、对证据强度的计算和综合等。相比CYC等本体知识库,Watson不构造基于形式逻辑推理的知识库,而是直接采用人类语言完成的知识,而且计算方式以统计推理为主,辅以规则方法和其它学习方法。这里面的核心技术有两个亮点值得一提:
1)多维度评价备选答案的可靠性,通过不同算法进行不同角度评价计算,如关键字匹配程度、时间关系的匹配程度、地理位置匹配的程度、问题类型的匹配程度等等。这就像医疗的疑难杂症诊断一样,各种检测指标、各种拍片、各种病理及病史的综合,才能得出更准确的诊断结果;
2)基于本体的语境和上下文的关联分析理解,例如要判断哈利波特是不是文学作品,从DBpedia语料库可以得出哈利波特是本小说,而小说是不是文学需要在本体或者说语义网络中去搜索,本体的各种逻辑关系,如层次关系、相交关系等是自然语言理解的基础。
三是进行现场问答的策略推演和决策:Watson会使用以往比赛的题库和模拟题库训练出一系列的中间模型,从中筛选出最有可能的备选答案,以加快现场答题的处理效率。
(3)非结构化信息管理框架(UIMA)
Watson平台开发还涉及UIMA,即非结构化信息管理框架(Unstructured Information Management Applications, UIMA)。UIMA的核心目标是分析大量非结构化数据以发现相关的知识。一个典型的UIMA应用程序可能会摄取纯文本并识别实体,如人员,地点,组织或关系,例如谁在什么地方工作,属于什么部门等等。UIMA使得一个大的应用程序能够被分解为若干小的组件,例如语音识别程序可以分为一系列组件,从语言识别,语言分段,句子边界检测到最终的实体检测(人/地名等)。每个组件实现由UIM框架定义接口,并通过XML提供描述元数据。UIM框架管理这些组件以及它们之间的数据流。一个典型的UIMA框架如下图:
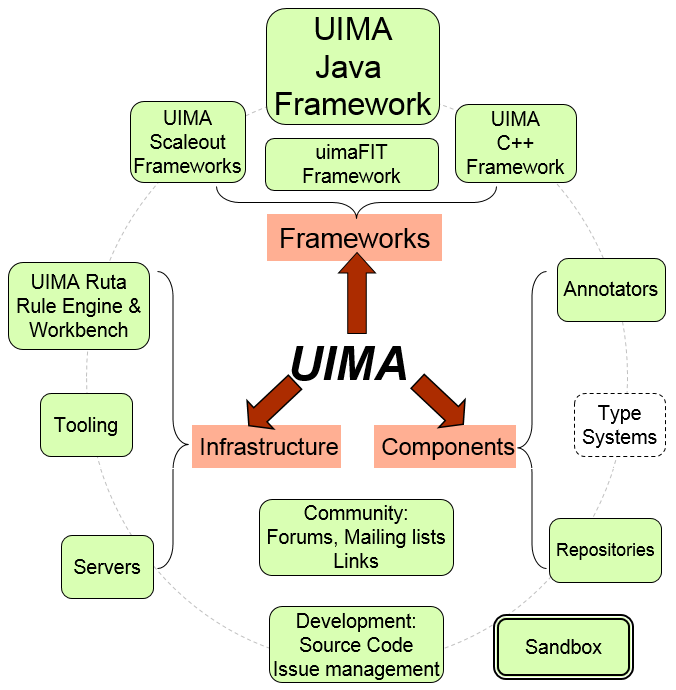
图13 UIMA技术框架图[9]
由于Watson系统的复杂性,设计了数百套算法和类似专家系统的模块组件,DeepQA团队设计了UIMA的异步扩展框架(UIMA-AS)来用于大量任务的并行计算,并通过JMS(Java Messaging Services)和ActiveMQ处理异步消息传递,使答案生成引擎可以方便地部署到多台服务器上并行处理,最终汇总分析结果。通过UIMA框架,Watson采用了90台IBMPower750服务器机器,才使得系统响应时间从2小时降到2-3秒。
(4)机器学习与深度学习
IBM豪赌数十亿美元树立沃森这杆AI大旗,从2006年诞生至今,一路走来并不顺利。其宣称的强大技术并不被大多数人认可。与世界顶级癌症研究机构MD Anderson之间的合作失败,更是给沃森的未来蒙上了一层阴影。这个事件引起了AI圈的广泛关注,当然很多是负面意见。比如有国外网友如此评价:“AI圈的人公开批评过Watson,因为相比核心技术它做得更多的是营销。有些人担心,Watson 会将机器学习或者AI置于一个可能让人抱有过高期望而后又失望的境地。现在看起来这些担忧成真了。我希望这件事不会进一步加深那些反对将机器学习用于医疗的人的观点。Watson一开始就是一个基于规则的系统,(据我所知)也是最近才开始增加深度学习的。”
当然也有IBM的工程师匿名评价了他家的“沃森”(Watson)和“狗”(AlphaGo)的智力,声称沃森和AlphaGo的智力对比,基本上是狗和人的对比,Watson虽是人名,但是在阿法狗的智商面前,他才是真的狗。这个评价笔者以前表示过认同,但通过对Watson核心技术的深入研究之后,应该没有那么不堪,相比阿尔法狗,沃森有它的劣势和强势,阿尔法狗(强化深度学习)和沃森(本体知识库、语料库)的深度融合能极大促进强人工智能的发展。只是在现阶段,沃森的核心技术并不被大多数人认可。其实Watson面对的,技术不是最大的问题,蓝色巨人的人才和管理问题才是最大的障碍。相比谷歌、亚马逊、特斯拉、Facebook等巨头,IBM在AI顶级人才的网罗和招揽方面可以说是完败。这不,今年7月杰富瑞投资银行(Jefferies& Co.)的分析师James Kisner就发布了一份关于Watson的投资分析报告[10],其中提到的一个关键问题就是IBM的AI人才不足。大数据智能时代,各个科技巨头都必须在人工智能、深度学习、数据挖掘等领域网罗顶级人才,这个问题并没有引起IBM的足够重视,仅以亚马逊为例,其公布的AI相关领域招聘职位已超过IBM的十倍。

图14 杰富瑞投资银行关于Watson的投资报告
尽管AlphaGo是以围棋作为挑战人类的样板工程,但DeepMind认为AlphaGo的核心技术也能被应用在其他的结构化问题上,例如蛋白质折叠、基因大数据分析、降低能源损耗,或是寻找革命性的新材料等等,谷歌也已经展开了与医疗机构的深度合作。笔者相信,这两个人类顶级的AI系统迟早会在医疗大数据领域一较高下。2015年,IBM拓展了Watson的深度学习功能,同年收购了AlchemyAPI,一家专门从事基于深度学习的文本和图像分析的公司。根据Watson的技术资料可以看出,其实沃森团队在研发过程中也尝试了一些机器学习和深度学习,具体细节笔者就不展开了。但可以肯定的是,自从沃森2006年首次研发以来,人工智能世界在发生巨大的变化,深度学习已经成为AI的主流技术,或许将重塑机器学习和人工智能,深度学习也正在自然语言处理领域大展拳脚。我想这一点,沃森的技术主管肯定是不会忽视的。
5. 沃森的强与弱
在分析沃森的能力之前,我们先看Watson宣传中经常用到的一个数据[5,7]:“一名专科医师要掌握当前最先进的医学成果,每天要看20篇文章;一个医学院学生,毕业之后五年内学到的知识可能有一半是过时的。此外,电子健康档案和电子病例会积累大量原始数据,这些数据对医生作更准确的诊断和提出治疗方法具有关键作用。但是人的认知能力和精力时间都是有限的,比如P53是与许多癌症有关的一种重要蛋白质,迄今已有70,000 篇有关这种蛋白质的论文。贝勒医学院研究院表示,即使科学家一天阅读五篇论文,也要花38年时间来全面了解这种蛋白质。而在中国医生少的情况下可能5分钟就要看一个病人,因为不了解医学的最新进展和病理相关的最新数据,实际诊断过程中的病人误诊率是很高的。”
 图15 Watson系统功能界面
图15 Watson系统功能界面
从技术角度来分析,这是大数据应用的巨大挑战,互联网上的数据多半是UGC用户产生内容,或是如电商平台这种某细分领域的独立生态数据,而真正的大数据金矿还在众多大型企业和政府、机构的服务器集群中沉睡。比如一个国家的情报部门和各部、各局信息中心,一个大型医院的海量数据库、文本库、图片库和病史记录,无不是掌握着成千上万关键领域的大数据,包括各种业务数据、监控数据、DNA样本、语音视频图片、地图时空数据等,面对如此海量、多源、异构而且高关联性、复杂性、动态性大数据,如果没有Watson这样的快速大数据分析技术和工具支持,那只能是望数兴叹。这个结论对于舆情分析、情报分析和公安、军事、金融等领域的应用需求同样成立[11]。从这个层面讲,沃森的大招远远没有发挥出来,唯一的问题是什么时候突破自然语言理解的技术瓶颈,或者说结构化数据与非结构化数据的融合处理分析瓶颈。所以技术本身的强和弱是很难比较的,取决于应用领域需求、技术选型和技术本身发展所处的阶段。难得是人才和管理,对高科技企业来讲,这是最大的问题。
 图16 Watson系统功能界面
图16 Watson系统功能界面
6. 总结与展望
从97年深蓝人机大战,07年沃森的发布到17年艰难前行中的沃森,IBM能否依托沃森认知智能,勇夺人工智能宝座而大象起舞?还难下定论。但笔者认为,蓝色巨人这个宝应该是押对了,不管是Palantir还是DeepMind都在聚焦认知智能,传统的自然语言处理技术能否和当前大热的深度学习、强化学习、迁移学习等技术深度融合发展,就看谁能抢先突破核心技术,还比拼的是技术、人才和管理等资源的保障。
总之,Palantir的人机共生重在结构化大数据的智能挖掘和分析;DeepMind的深度强化学习重在人类学习方式的解构;而Watson的认知智能重在海量语料库、知识库的自然语言统计推理和本体关联学习。IT巨头们的核心技术可谓是八仙过海、各显神通,条条大路通罗马,目标都一样,直指人工智能。
来源:点金大数据 | 备注:本文图片来源于网络
参考文献:
1.Matthew Herper,MD Anderson Benches IBM Watson In Setback For Artificial Intelligence In Medicine,Forbe
2.Building Watson: An Overview of the DeepQA Project, https://www.aaai.org/Magazine/Watson/watson.php
3.Watson (computer) Wiki百科词条, https://en.wikipedia.org/wiki/Watson_(computer)
4.从Watson看AI平台的架构设计 http://blog.csdn.net/dev_csdn/article/details/78426133
5.专访超级电脑“沃森”系统背后的中国团队 http://tech.163.com/11/0309/14/6UNA2RAH0009387J.html
6.Watson百度百科词条 https://baike.baidu.com/item/Watson
7.Watson的独特“思考”, http://history.programmer.com.cn/13468/
8.How Much Artificial Intelligence Does IBM Watson Have? https://seekingalpha.com/article/4087604-much-artificial-intelligence-ibm-watson
9.Apache UIMA,http://uima.apache.org/
10.IBM Creating Shareholder Value with AI? Not so Elementary, My Dear Watson https://javatar.bluematrix.com/pdf/fO5xcWjc
11.大数据独角兽Palantir之核心技术探秘 http://www.datagold.com.cn/archives/7204.html
12.深度智能的崛起 http://www.datagold.com.cn/archives/9375.html
版权声明:本站原创和会员推荐转载文章,仅供学习交流使用,不会用于任何商业用途,转载本站文章请注明来源、原文链接和作者,否则产生的任何版权纠纷与本站无关,如果有文章侵犯到原作者的权益,请您与我们联系删除或者进行授权,联系邮箱:service@datagold.com.cn。

